python实现dbscan算法
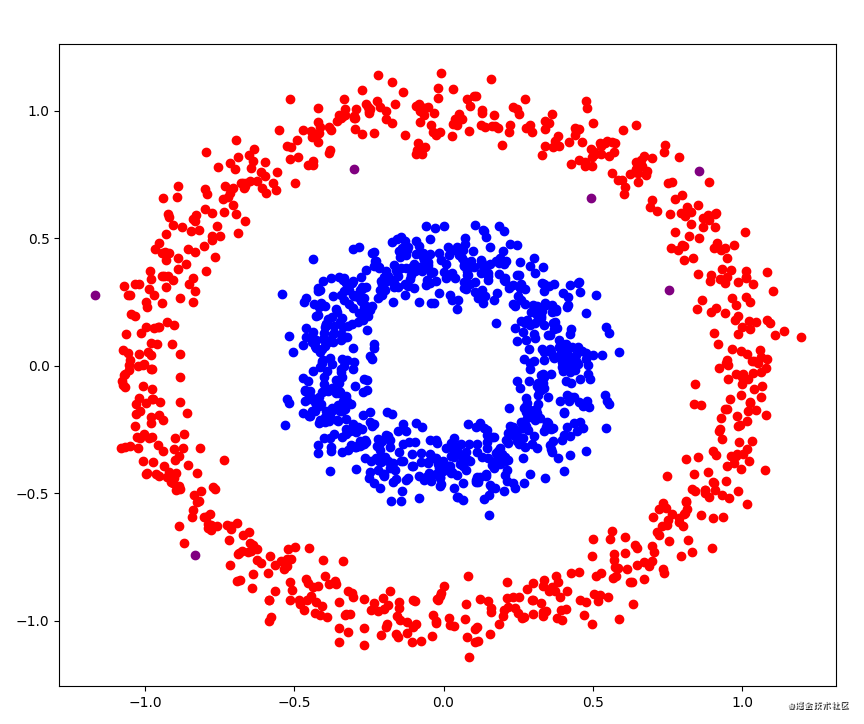
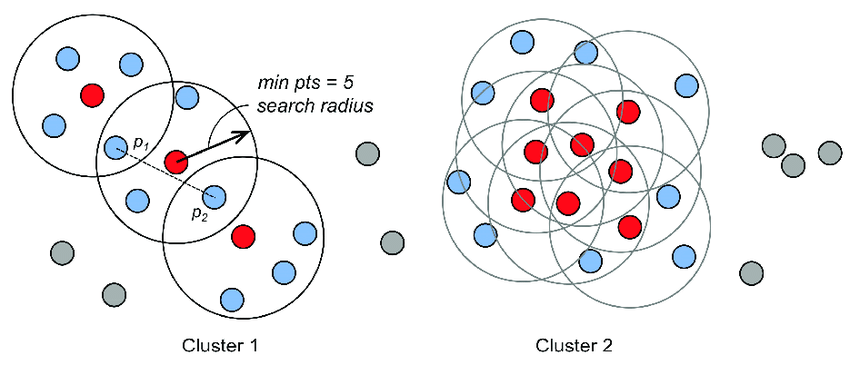
DBSCAN 算法是一种基于密度的空间聚类算法。该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其它空间对象)的数目不小于某一给定阀值。DBSCAN 算法的显著优点是聚类速度快且能够有效处理噪声点和发现任意形状的
2024-11-16
怎么在python中实现dbscan算法
今天就跟大家聊聊有关怎么在python中实现dbscan算法,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。DBSCAN 算法是一种基于密度的空间聚类算法。该算法利用基于密度的聚类的概
2024-11-16
深度解读Python如何实现dbscan算法
DBScan 是密度基于空间聚类,它是一种基于密度的聚类算法,其与其他聚类算法(如K-Means)不同的是,它不需要事先知道簇的数量。本文就来带大家了解一下Python是如何实现dbscan算法,感兴趣的可以了解一下
2024-11-16
Python实现DBSCAN聚类算法并样例测试
什么是聚类算法
聚类是一种机器学习技术,它涉及到数据点的分组。给定一组数据点,我们可以使用聚类算法将每个数据点划分为一个特定的组。理论上,同一组中的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征。聚类
2024-11-16
Python中怎么利用DBSCAN实现一个密度聚类算法
Python中怎么利用DBSCAN实现一个密度聚类算法,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。基于密度这点有什么好处呢?我们知道kmeans聚类算法只能处理球形的簇,也就
2024-11-16
Python中DBSCAN怎么实现
在Python中,可以使用scikit-learn库来实现DBSCAN算法。下面是一个简单的DBSCAN算法实现的示例:```pythonfrom sklearn.cluster import DBSCANfrom sklearn.data
2024-11-16
Python怎么取读csv文件做dbscan分析
本篇内容介绍了“Python怎么取读csv文件做dbscan分析”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!1.读取csv数据做dbsca
2024-11-16
python 算法
算法的复杂度算法的时间复杂度是指算法需要消耗的时间资源时间复杂度用“O(数量级)”来表示常见的时间复杂度有:O(1)常数阶; 问题规模越大效率越高,时间不变, a = [1,2,3] a[0]=1,a增加无影响O(log2n)对数阶:
2024-11-16
python 基本算法
一.无序表查找def sequential_search(lis, key): for i in lis: if i == key: return lis.index(i) else:
2024-11-16
python冒泡算法
import random#用random和range生成30个数的一个列表lis = []for i in range(10): n = random.randint(1,1000) lis.append(n)#查看原有列表p
2024-11-16
Python排序算法之堆排序算法
堆排序看字面意思是一种排序方法,那堆是什么呢?堆是一个近似完全二叉树的结构,并同时满足堆积的性质。其实堆排序是指利用堆这种数据结构所设计的一种排序算法。
2024-11-16
LeetCode算法题python解法:
英文题目:The string "PAYPALISHIRING" is written in a zigzag pattern on a given number of rows like this: (you may want to di
2024-11-16
python算法演练_One Rule 算法(详解)
这样某一个特征只有0和1两种取值,数据集有三个类别。当取0的时候,假如类别A有20个这样的个体,类别B有60个这样的个体,类别C有20个这样的个体。所以,这个特征为0时,最有可能的是类别B,但是,还是有40个个体不在B类别中,所以,将这个特
2024-11-16
dijkstra算法python实现
MAX_value = 999999def dijkstra(graph, s): # 判断图是否为空,如果为空直接退出 if graph is None: return None dist = [MAX_v
2024-11-16
LRU算法——python实现
在LeetCode上看到这么一道题:Design and implement a data structure for Least Recently Used (LRU) cache. It should support the follo
2024-11-16
python排序算法(三)
OK,又到了苦逼的周一了。快排比较复杂,花了快两天琐碎时间琢磨了感觉还不是很好,据我们老师说当年提出快排的人是在上课突然想起来的,我等只能深深膜拜了 快速排序是一种具有良好平均性能的排序方法,插入排序将控制当前插入的基准记录插入相对于
2024-11-16
























![[mysql]mysql8修改root密码](https://static.528045.com/imgs/31.jpg?imageMogr2/format/webp/blur/1x0/quality/35)





